2022. 9. 19. 15:43ㆍ🛠 Data Engineering/Apache Airflow

저번 포스팅에선 airflow와 spark을 연동하는 방법에 대해 알아봤습니다. 이번 포스팅에선 간단한 실습을 바로 진행해보도록 하겠습니다.
* 본 포스팅은 해당 강의를 참고한 것임을 밝힙니다.
[pyspark 세팅하러 가기]
https://mengu.tistory.com/25?category=932924
[Spark] 초기 환경 세팅 ft. 호환 문제 해결
이번 포스팅은 Spark 초기 환경 세팅이다. Spark, pyspark, java 등 그냥 설치해서 끝내면 되는 거 아니냐 할 수 있지만, 중간에 버전 호환 문제가 존재해서 막힐 수 있다. 그 부분을 집어주고자 포스팅
mengu.tistory.com
[Airflow&Spark 연동하러 가기]
[Airflow] Airflow & Spark 연동해서 활용하기 (1)
이번 포스팅에선 Airlfow와 Spark의 연동에 대해 다루겠습니다. Spark에서의 작업을 Airflow를 통해 자동화시키는 작업까지 해보겠습니다. 당연히 Airlflow와 pyspark 환경이 세팅되어 있어야 합니다. * 본
mengu.tistory.com
목차
📃 Airflow x Spark 연동 원리
📃 연동하기
📃 mini project
mini project
TLC trip data로 간단한 실습을 해보겠습니다.
Airflow를 통해 자동화할 파이프라인은 다음과 같습니다.
(1) Data preprocessing
데이터를 알맞게 가공합니다.
(2) Data Analytics & Report
가공된 데이터를 바탕으로 프로그램이 분석하고, 보고서 파일을 생성합니다.
📌 데이터 다운로드하기
https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
TLC Trip Record Data - TLC
TLC Trip Record Data Yellow and green taxi trip records include fields capturing pick-up and drop-off dates/times, pick-up and drop-off locations, trip distances, itemized fares, rate types, payment types, and driver-reported passenger counts. The data use
www1.nyc.gov
(1) 사이트에 접속해서 2021.01 데이터를 다운로드하여줍니다. 빨간 사각형을 다운받아 주세요.

(2) 파일을 자신이 원하는 폴더에 넣어줍니다.
📌 Spark 작업 작성
(1) preprocess.py
SparkSession을 불러오고, 파일을 불러옵니다.
여러 변수들에 대해, 이상치들을 제거해주고 다시 parquet 파일로 구워줍니다.
# spark 찾아오기
import findspark
findspark.init()
# 패키지를 가져오고
from pyspark import SparkConf, SparkContext
import pandas as pd
from pyspark.sql import SQLContext
from pyspark.sql import SparkSession
MAX_MEMORY="5g"
spark = SparkSession.builder.appName("taxi-fare-prediciton")\
.config("spark.executor.memory", MAX_MEMORY)\
.config("spark.driver.memory", MAX_MEMORY)\
.getOrCreate()
trip_files = "데이터 파일 경로.parquet"
trips_df = spark.read.parquet(f"file:///{trip_files}", inferSchema=True, header=True)
trips_df.show(5)
trips_df.createOrReplaceTempView("trips")
query = """
SELECT
PULocationID as pickup_location_id,
DOLocationID as dropoff_location_id,
trip_miles,
HOUR(Pickup_datetime) as pickup_time,
DATE_FORMAT(TO_DATE(Pickup_datetime), 'EEEE') AS day_of_week,
driver_pay
FROM
trips
WHERE
driver_pay < 5000
AND driver_pay > 0
AND trip_miles > 0
AND trip_miles < 500
AND TO_DATE(Pickup_datetime) >= '2021-01-01'
AND TO_DATE(Pickup_datetime) < '2021-08-01'
"""
data_df = spark.sql(query)
data_dir = "데이터 파일 폴더"
data_df.write.format("parquet").mode('overwrite').save(f"{data_dir}/")
(2) Analytics.py
전처리를 끝냈다면, 파일을 불러와서 분석을 시작합니다.
이번 포스팅에선 간단하게 를 그리고 저장하는 것으로 하겠습니다.
# spark 찾아오기
import findspark
findspark.init()
from pyspark.sql import SparkSession
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
MAX_MEMORY="10g"
spark = SparkSession.builder.appName("taxi-fare-prediciton")\
.config("spark.executor.memory", MAX_MEMORY)\
.config("spark.driver.memory", MAX_MEMORY)\
.getOrCreate()
data_dir = "/home/mingu/airflow/data-engineering/02-airflow/data/"
data_df = spark.read.parquet(f"{data_dir}/data/")
# 데이터 createOrReplaceTempView()
data_df.createOrReplaceTempView("trips")analytics 파일도 처음 부분은 똑같습니다. 데이터를 다루기 위해 createOrReplaceTempView()를 해줘야 합니다.
이제 각종 그래프를 그릴 시간입니다.
그래프를 그리면 바로 원하는 폴더에 저장합니다.
(1) 거리, 요금과의 산포도 그래프
# 1. trip_miles 와 driver_pay 간의 산포도 그래프
miles_pay = spark.sql("SELECT trip_miles, driver_pay FROM trips").toPandas()
fig, ax = plt.subplots(figsize=(16,6))
plt.title('miles_pay', fontsize = 30)
sns.scatterplot(
x = 'trip_miles',
y = 'driver_pay',
data = miles_pay
)
plt.savefig("result/miles_pay.png")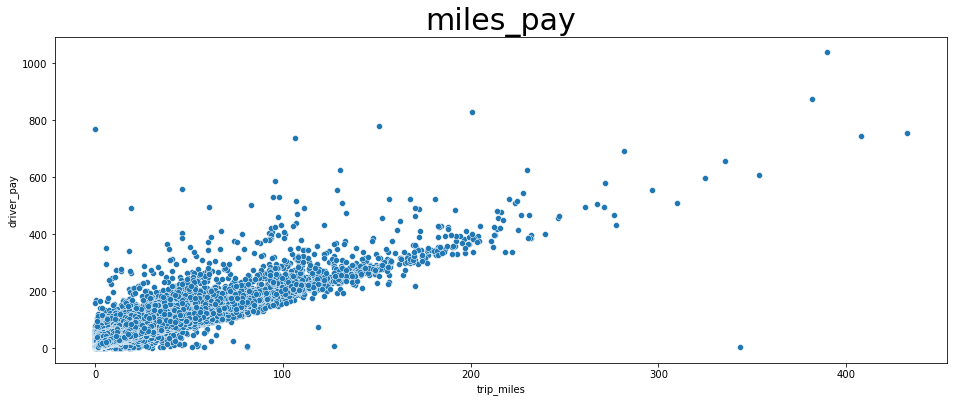
(2) 요일별 거리/요금 그래프
# 2. 요일별 거리, 요금 그래프
weekday_df = spark.sql("SELECT day_of_week, MEAN(trip_miles) as distance_mean, MEAN(driver_pay) AS fare_mean from trips GROUP BY day_of_week").toPandas()
for i in ['distance_mean', 'fare_mean']:
fig, ax = plt.subplots(figsize=(16,6))
plt.title(i, fontsize = 30)
sns.barplot(
x = 'day_of_week',
y = i,
data = weekday_df
)
plt.savefig(f"result/{i}.png")
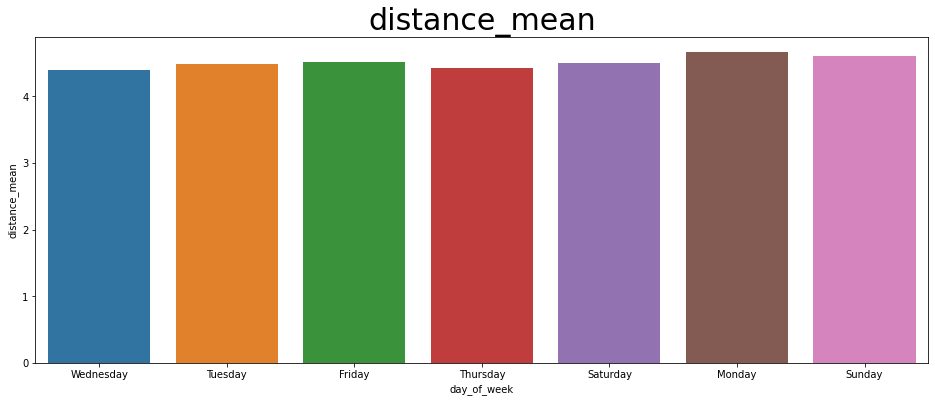
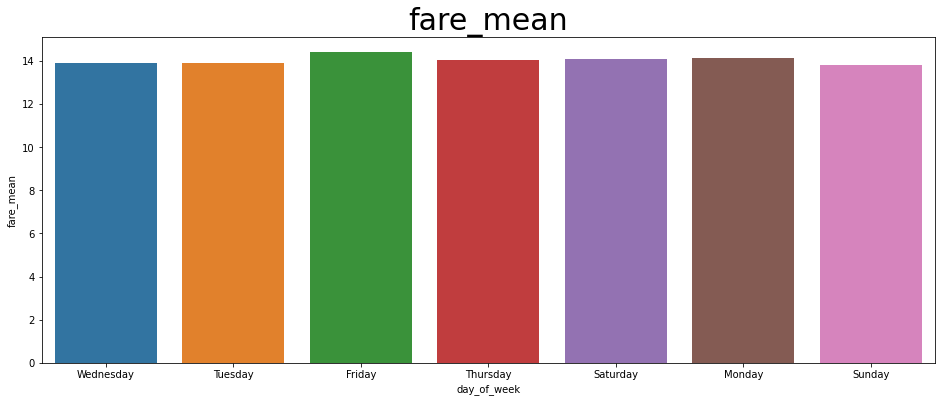
(3) 요일별 택시 승객 수 그래프
# 3. 요일별 택시 count 그래프
week_count = spark.sql("SELECT day_of_week, COUNT(day_of_week) as count FROM trips GROUP BY day_of_week").toPandas()
fig, ax = plt.subplots(figsize=(16,6))
plt.title('week_count', fontsize = 30)
sns.barplot(
x = 'day_of_week',
y = 'count',
data = week_count
)
plt.savefig("result/week_count.png")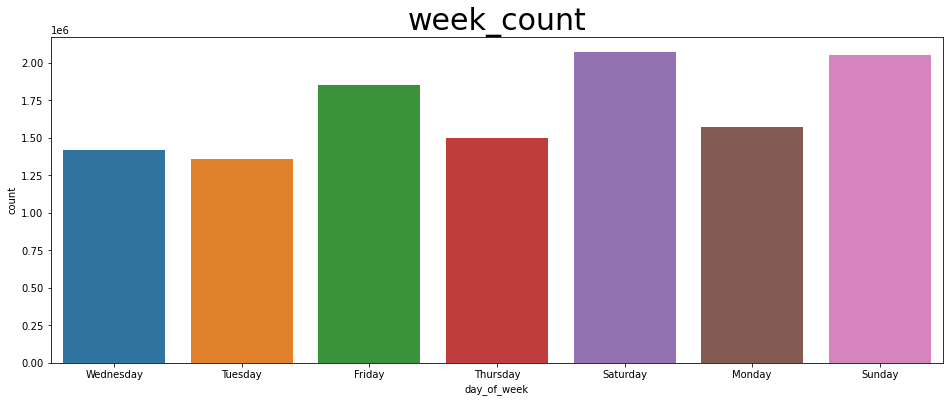
(4) 시간별 승객 수 그래프
# 4. pickup_time 그래프
time_count = spark.sql("SELECT pickup_time, COUNT(pickup_time) as count FROM trips GROUP BY pickup_time").toPandas()
fig, ax = plt.subplots(figsize=(16,6))
plt.title('time_count', fontsize = 30)
sns.barplot(
x = 'pickup_time',
y = 'count',
data = time_count
)
plt.savefig("result/time_count.png")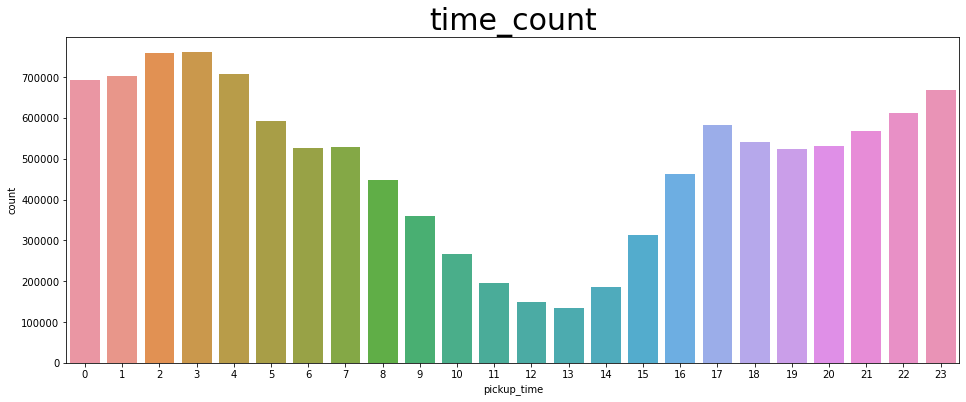
📌 Airflow를 통한 연결
Airflow DAG를 작성해줄 시간입니다.
SparkSubmitOperator()을 이용해서 preprocess.py, analytics.py 파일들을 실행하도록 연결하겠습니다.
(1) 첫 세팅
from datetime import datetime
from email.mime import application
from airflow import DAG
# from airflow.providers.apache.spark.operators.spark_sql import SparkSqlOperator
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator
from datetime import datetime
default_args = {
'start_date' : datetime(2022,9,16)
}
(2) DAG 입력
conn_id는 이전 포스팅에서 생성한 connection id입니다. application은 실행하고자 하는 파일의 경로를 입력해주시면 됩니다. task_id는 말 그대로 DAG에 명시할 Task를 입력해두시면 됩니다.
의존성 표시도 잊지 말고 해 주세요!
with DAG(dag_id="spark-airflow example",
schedule_interval='@daily',
default_args=default_args,
tags=['spark'],
catchup=False) as dag :
# preprocess
preprocess = SparkSubmitOperator(
application = "/home/mingu/airflow/blogs/preprocessing.py",
task_id = "preprocess",
conn_id = "spark_local"
)
# analytics
analytics = SparkSubmitOperator(
application = "/home/mingu/airflow/blogs/analytics.py",
task_id = "analytics",
conn_id = "spark_local"
)
preprocess >> analytics
(2) 전체 코드
from datetime import datetime
from email.mime import application
from airflow import DAG
# from airflow.providers.apache.spark.operators.spark_sql import SparkSqlOperator
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator
from datetime import datetime
default_args = {
'start_date' : datetime(2022,9,16)
}
with DAG(dag_id="spark-airflow example",
schedule_interval='@daily',
default_args=default_args,
tags=['spark'],
catchup=False) as dag :
# preprocess
preprocess = SparkSubmitOperator(
application = "/home/mingu/airflow/blogs/preprocessing.py",
task_id = "preprocess",
conn_id = "spark_local"
)
# analytics
analytics = SparkSubmitOperator(
application = "/home/mingu/airflow/blogs/analytics.py",
task_id = "analytics",
conn_id = "spark_local"
)
preprocess >> analytics
📌 실행
먼저 2개의 cmd에 다음 명령어들을 입력해줍니다.
airflow webserverairflow scheduler
localhost:8080으로 접속!
spark-airflow DAG로 이동한 후, 실행시키면?
잘 진행되는 것을 보실 수 있습니다.
또한 작업이 끝나면 이렇게 result 폴더에 파일들이 생성됩니다.
지금까지 Airflow&Spark 연동 및 활용을 해보았습니다.
혹여나 Analytics.py를 실행하던 중, 메모리 초과 문제를 일으키는 경우가 있습니다. 이 경우, 거리와 요금의 산포도 데이터가 너무 큰 나머지 용량을 초과하기 때문에 발생하는 것입니다. 파일 자체의 용량을 줄이던지, 아예 거리/요금 데이터는 생성하지 않음으로써 문제를 해결할 수 있습니다. 다른 그래프들은 용량이 적어 원활하게 작동할 것입니다!
'🛠 Data Engineering > Apache Airflow' 카테고리의 다른 글
| [Airflow] Airflow & Spark 연동해서 활용하기 (1) (0) | 2022.09.17 |
|---|---|
| [Airflow] Airflow 기초 지식 (0) | 2022.09.15 |
| [Airflow Error] 403:Forbidden (0) | 2022.09.08 |