2024. 5. 27. 22:52ㆍ🧪 Data Science/ML, DL
강화학습에 대해 공부하고 있어, 여러 알고리즘의 수식과 코드를 정리하고자 한다.
이 포스팅은 첫 발걸음이며, REINFORCE 알고리즘에 대해 다루겠다.
파이팅!
본 포스팅은 책 Foundation of Deep Reinforcement Learning / laura.G에서 수식 및 내용을 참고하여 쓰인 글입니다.

1. REINFORCE 개념
1.1. Model-free vs Model-Based
강화학습은 크게 Model-free, Model-Based로 나뉜다. Model-Based 강화학습은 trajectory를 예측하는 모델을 기반으로 학습한다. 다양한 가짓수의 action에 대한 확률 높은 trajectory를 예측할 수 있는데, 이 경우 무작위로 sampling 된 trajectory를 학습하는 Model-free보다 더 빠르게 목표물에 접근할 수 있고 승패가 분명하게 존재하는 상황에선 효율적으로 작용한다.
하지만 많은 실제 상황은 stochastic 한 경우가 많으며, 하나의 수식 및 model로 나타낼 수 없는 경우가 흔하다. good model에 대한 기준도 명확하지 않아, Model-free 방식이 더 활발하게 연구되고 있으며 REINFORCE 또한 Model-free 방식으로 학습한다.
1.2. Policy-optimization
Policy-optimization이 REINFORCE의 핵심이다. Policy를 최적화하는 문제이다. 그중, policy-gradient에 대해 설명하겠다. 아래 그림을 살펴보자. State(t)가 주어졌을 때, Agent는 Action(t)를 행한다. 이에 대해 Reward(t)가 주어진다. 한 Trajectorty는 다양한 시간대의 timestep을 담고 있으며, 각 시간대의 Reward를 Discount Sum하여 기대치를 나타낸 것이 J(t) 목적함수이다. 이 목적함수를 maximize하는 정책을 만들어 가는 것이 Policy-optimization이라고 이해하면 되겠다. 그 중 목적함수 결과를 policy에 적용하여 업데이트해나가는 것을 policy-gradient 알고리즘이라고 한다.

1.3. Policy-gradient needs three components
1) A parametrized policy
2) An objective to be maximized
3) A method for updating the policy parameters
위에서 소개한 polilcy-gradient 알고리즘은 3개의 구성요소를 필요로 한다. 업데이트를 할 policy, policy를 조정할 objective function, 조정하는 방법(policy-gradient) 등이다. policy는 states에 대하여 action probabilities를 매핑한 함수이다.
업데이트가 될수록 높은 reward를 도출하는 > trajectory를 구성하는 > action의 probabilities가 높게 나오는 policy가 될 것이다.
2. REINFORCE 안의 수식
2.1. Policy
$ \pi_{\theta} = policy $
$\pi$는 policy 함수 그 자체이며, $\theta$가 learnable parameters이다.
'We say that the policy is parameterized by $\theta$ '
당연히
(( \pi_{\theta_{1}} \neq \pi_{\theta_{2}} ))
위의 식이 성립한다. 파라미터 자체가 달라 아예 다른 policy이기 때문이다.
2.2. The Objective Function
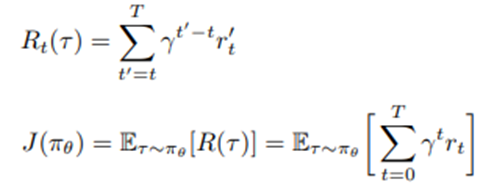
$R_{t}(\tau)$ 는 특정 trajectory에서 받는 reward의 discounted sum이다. 그리고 모든 timestep에 대하여 구했던 Reward 합의 기댓값이 목적함수가 된다.
2.3. The Policy Gradient
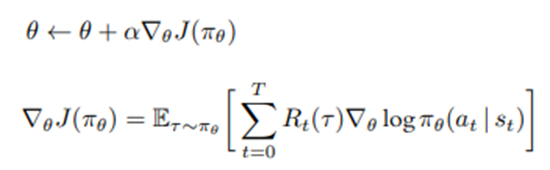
policy의 parameter인 $\theta$는 목적함수의 미분 결과 즉, 목적함수의 증감소분으로 업데이트된다.
$\alpha$는 learning rate이다.
목적함수의 미분은 사실 조금 더 복잡한 연산에 의해 유도되지만, 굳이 설명하지는 않겠다. 최종 형태만 이해하고 넘어가겠다.
2.4. Monte Carlo Sampling
Monte Carlo 샘플링은 무수히 많은 샘플을 뽑아, 값을 평균내면 최종 값에 근사할 수 있다는 이론이다.
길이가 2인 정사각형 안에 반지름이 1인 원이 내접해 있다고 가정하자. 이들의 넓이 비는 아래 식과 같이 계산된다.
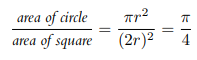
하지만 만약 반지름 길이를 모른다고 가정할 경우, 어떻게 넓이 비를 계산할 수 있을까. 사각형 안에 무수히 많이 점을 randomly 하게 찍고, 원에 들어가 있는 점의 개수를 총점의 개수로 나누면 근사를 구할 수 있을 것이다.

이것이 바로 Monte Carlo Sampling 기업이며, $\tau$ (trajectory)를 sampling 할 때 이용된다.
3. REINFORCE Algorithms
3.1. Basic
REINFORCE 알고리즘은 다음과 같은 코드를 띤다.

episode는 상황을 말한다. episode가 100일 경우, 100번의 학습 과정을 거친다고 보면 된다. 지도 학습 기준으론 epoch라고 할 수 있다.
(1) 각 episode 안에서 랜덤 하게 $\tau$를 뽑는다.
(2) 목적 함수의 미준을 초기화한 상태에서
(3) time 별 reward와 목적함수를 구한다. 그 안에서 목적함수의 증감소분은 계속해서 업데이트된다.
(4) 하나의 episode가 끝나면 $\theta$ (parameters of policy)를 업데이트한다.
(5) 모든 episode가 끝다면 학습은 종료된다.
3.2. Improving
하지만 문제가 존재한다. Monte Carlo Sampling으로 $\tau$를 뽑을 경우, trajectory마다 reward가 매우 다르게 나올 것이다. 그에 따라 high variance 문제가 생긴다. 이 문제를 해결하기 위해 reward scaling 중 하나인 reward normalization을 진행한다. 대표적인 형태는 다음과 같다.
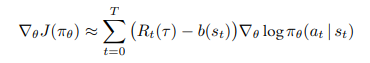
단순한 개념으로, reward에 특정 값을 빼주는 것이다. 흔히 $ E(\sum R_{t}(\tau )) $를 쓴다. reward의 평균을 사용하여, centering returns for each trajectory around 0 한다.
이 과정을 통해, high variance 문제를 어느 정도 해소할 수 있다.
'🧪 Data Science > ML, DL' 카테고리의 다른 글
| [강화학습] SARSA와 DQN 개념 정리 (0) | 2024.07.05 |
|---|---|
| [강화학습] REINFORCE 알고리즘 : 코드 구현 (1) | 2024.06.02 |
| [ML] 차원 축소 (1) - 정의, PCA, 예제코드 (1) | 2024.02.26 |
| [추천 알고리즘] ALS 개념, Basic 하게 feat. 코드 X (0) | 2022.05.23 |
| [CNN basic] MNIST 데이터셋 학습, 예측 (0) | 2022.04.19 |