2022. 5. 25. 19:38ㆍ🧪 Data Science/Analytics

당신은 NEWYORK에서 택시 기사로 일하고 있다.
택시는 Yellow Taxi이다.
택시 기사로 생존하기 위해선 다음과 같은 노력이 필요하다.
1) 근무 시간 동안, 손님을 최대한 많이 태울 것 (손님)
2) 많은 요금 + 풍부한 팁 (요금)
3) 현금 결제는 소득에 포함시키지 않고 슬쩍하기 (세금 절약)
첫 번째 노력은 이전 포스팅에서 다뤘다.
이번 포스팅에선 많은 요금과 팁을 받는 방법, 현금 결제하는 손님을 받는 방법을 알아보겠다.
[Data]
데이터는 SparkSQL 포스팅에서 전 처리한 Yellow Taxi 데이터(cleaned)를 사용하도록 하겠다.
NEWYORK Yellow Taxi의 운행을 2021.01~2021.07까지 모두 모아놓은 데이터다.
[Yellow Taxi Data: https://mengu.tistory.com/50]
[SparkSQL] 택시 데이터 다운/전처리/분석 feat. TLC
이전 포스팅에서 공부한 SparkSQL 지식을 바탕으로, 실제 Taxi 데이터를 전처리해보자. * 전처리란? 이상치 제거, 그룹화 등 데이터 분석이 용이하도록 데이터를 변형하는 과정을 말한다. TLC Trip Recor
mengu.tistory.com
Basic Setting
from matplotlib import font_manager, rc
font_path = 'C:\\WINDOWS\\Fonts\\HBATANG.TTF'
font = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font)
import os
import findspark
findspark.init(os.environ.get("SPARK_HOME"))
import pyspark
from pyspark import SparkConf, SparkContext
import pandas as pd
import faulthandler
faulthandler.enable()
from pyspark.sql import SparkSession
spark = SparkSession.builder.master('local').appName("taxi-analysis").getOrCreate()
# 데이터가 있는 파일
zone_data = "C:/DE study/data-engineering/01-spark/data/taxi_zone_lookup.csv"
trip_files = "C:/DE study/data-engineering/01-spark/data/trips/*"
# 데이터 로드
trips_df = spark.read.csv(f"file:///{trip_files}", inferSchema = True, header = True)
zone_df = spark.read.csv(f"file:///{zone_data}", inferSchema = True, header = True)
# 데이터 스키마
trips_df.printSchema()
zone_df.printSchema()
# 데이터 createOrReplaceTempView()
trips_df.createOrReplaceTempView("trips")
zone_df.createOrReplaceTempView("zone")
# 쓸만한 column만 모아놓자.
query = '''
SELECT
t.VendorID,
TO_DATE(t.tpep_pickup_datetime) AS pickup_date,
HOUR(t.tpep_pickup_datetime) AS pickup_time,
TO_DATE(t.tpep_dropoff_datetime) AS dropoff_date,
HOUR(t.tpep_dropoff_datetime) AS dropoff_time,
t.passenger_count,
t.trip_distance,
t.payment_type,
t.fare_amount,
t.tip_amount,
t.tolls_amount,
t.total_amount,
pz.Zone as pzone,
dz.Zone as dzone
FROM
trips t
LEFT JOIN
zone pz
ON
t.PULocationID == pz.LocationID
LEFT JOIN
zone dz
ON
t.DOLocationID == dz.LocationID
'''
taxi_df = spark.sql(query)
taxi_df.createOrReplaceTempView("taxi")
spark.sql('select * from taxi').show(5)
+--------+-----------+-----------+------------+------------+---------------+-------------+------------+-----------+----------+------------+------------+-----------------+--------------+
|VendorID|pickup_date|pickup_time|dropoff_date|dropoff_time|passenger_count|trip_distance|payment_type|fare_amount|tip_amount|tolls_amount|total_amount| pzone| dzone|
+--------+-----------+-----------+------------+------------+---------------+-------------+------------+-----------+----------+------------+------------+-----------------+--------------+
| 2| 2021-03-01| 0| 2021-03-01| 0| 1| 0.0| 2| 3.0| 0.0| 0.0| 4.3| NV| NV|
| 2| 2021-03-01| 0| 2021-03-01| 0| 1| 0.0| 2| 2.5| 0.0| 0.0| 3.8| Manhattanville|Manhattanville|
| 2| 2021-03-01| 0| 2021-03-01| 0| 1| 0.0| 2| 3.5| 0.0| 0.0| 4.8| Manhattanville|Manhattanville|
| 1| 2021-03-01| 0| 2021-03-01| 0| 0| 16.5| 1| 51.0| 11.65| 6.12| 70.07|LaGuardia Airport| NA|
| 2| 2021-03-01| 0| 2021-03-01| 0| 1| 1.13| 1| 5.5| 1.86| 0.0| 11.16| East Chelsea| NV|
+--------+-----------+-----------+------------+------------+---------------+-------------+------------+-----------+----------+------------+------------+-----------------+--------------+
only showing top 5 rows
# cleaning -------------------------------------------------------------------
# data clearning
# fare, tip, tolls 에 대한 것은 나중에 df 만들때 전처리해주자.
query = '''
SELECT
*
FROM
taxi t
WHERE
t.total_amount < 2000
AND t.total_amount > 0
AND t.trip_distance < 100
AND t.passenger_count < 6
AND t.pickup_date >= '2021-01-01'
AND t.pickup_date < '2021-08-01'
AND t.dropoff_date >= '2021-01-01'
AND t.dropoff_date < '2021-08-03'
'''
df_c = spark.sql(query)
df_c.createOrReplaceTempView('cleaned')
전략 2. 많은 요금 & 많은 팁
많은 손님을 받으면서, 요금과 팁까지 많이 벌어들일 수 있다면 수입이 쏠쏠할 것이다.
어떤 상황에서 요금과 팁이 많이 나올까? 요금과 팁이 높은 경우를 분석해보고, 더나아가 일부 칼럼 만으로 요금과 팁을 예측해보자. 손님이 콜했을 때, 요금과 팁이 많이 나올 것으로 예측하면 콜을 수락하는 API를 만들어보자.
(1) 요금 & 팁 분석
A. 요일과 fare, distance, tip의 관계
먼저 요일별로 fare, distance, tip의 평균을 비교했다.
월화수목금토일은 거리, 요금, 팁에 영향을 줬을까?
# 요일별 fare, distance, tip 평균
query = '''
SELECT
DATE_FORMAT(c.pickup_date, 'EEEE') AS day_of_week,
MEAN(c.trip_distance) AS distance_mean,
MEAN(c.fare_amount) AS fare_mean,
MEAN(c.tip_amount) AS tip_mean
FROM
cleaned c
GROUP BY
day_of_week
'''
weekday_df = spark.sql(query).toPandas()
# 그래프 그리기
for i in ['distance_mean', 'fare_mean', 'tip_mean']:
fig, ax = plt.subplots(figsize=(16,6))
plt.title(i, fontsize = 30)
sns.barplot(
x = 'day_of_week',
y = i,
data = weekday_df
)
요일별 거리는 월요일 -> 일요일로 향할수록 커진다. 주말에 출퇴근보단 색다른 곳에 놀러 가거나 먼 곳에 볼 일을 가는 일이 더 많아서 이런 양상이 나온 것으로 보인다.
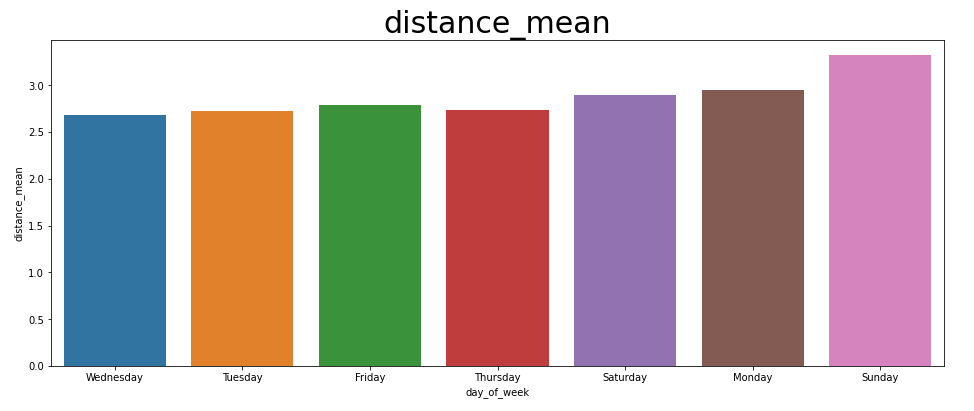
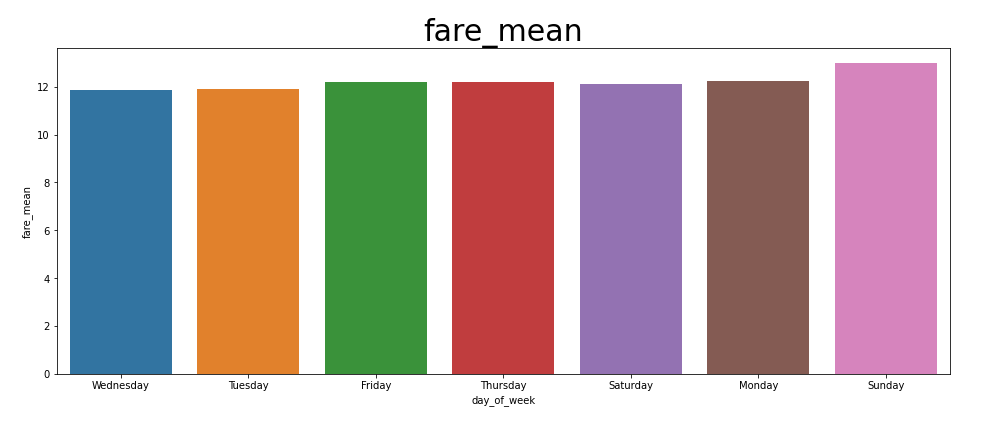
fare는 요일별로 크게 차이가 나보이지 않는다. fare가 distance처럼 월요일 -> 일요일로 커지는 양상을 띠지만, distance가 커졌기에 당연한 수순이다. 요일 자체가 fare에 큰 영향을 주는 것 같지는 않다..
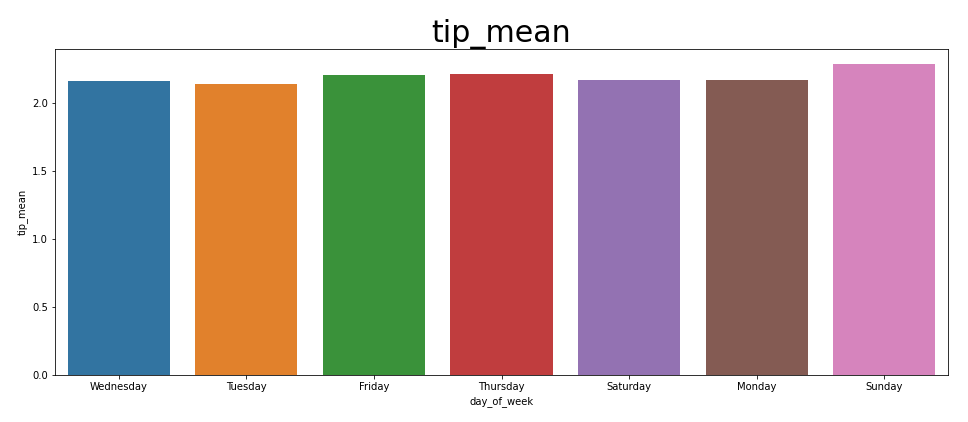
fare에 반해, 팁은 유의미하다고 볼 수 있다. 애초에 팁은 보너스의 느낌이기에 1달러만 받아도 개꿀이다. 일요일에 사람들이 기분이 좋은지 tip을 더 많이 준다. 어라? 앞에서 거리가 일요일로 갈수록 늘어났다. 팁도 월요일 -> 일요일로 갈수록 조금씩 늘어나는 양상인데, 그렇다면 tip과 distance가 관계있는 것이 아닐까?
B. Distance와 Fare, Tip 과의 관계
거리와 요금 및 팁 사이의 관계를 밝히기 위해 산포도 그래프를 그렸다. 이어 피어슨 상관계수를 사용한 후, 히트맵을 그렸다.
query = '''
SELECT
c.trip_distance,
c.fare_amount,
c.tip_amount
FROM
cleaned c
WHERE
c.fare_amount > 0
AND c.fare_amount < 100
AND c.tip_amount > 0
AND c.tip_amount < 100
'''
distance_df = spark.sql(query).toPandas()
for i in ['fare_amount', 'tip_amount']:
fig, ax = plt.subplots(figsize=(16,6))
plt.title(i, fontsize = 30)
sns.scatterplot(
x = 'trip_distance',
y = i,
data = distance_df
)
fig, ax = plt.subplots(figsize=(16,6))
plt.title("Person Correlation of Features", fontsize = 30)
sns.heatmap(distance_df.corr(), cmap=colormap, annot=True)
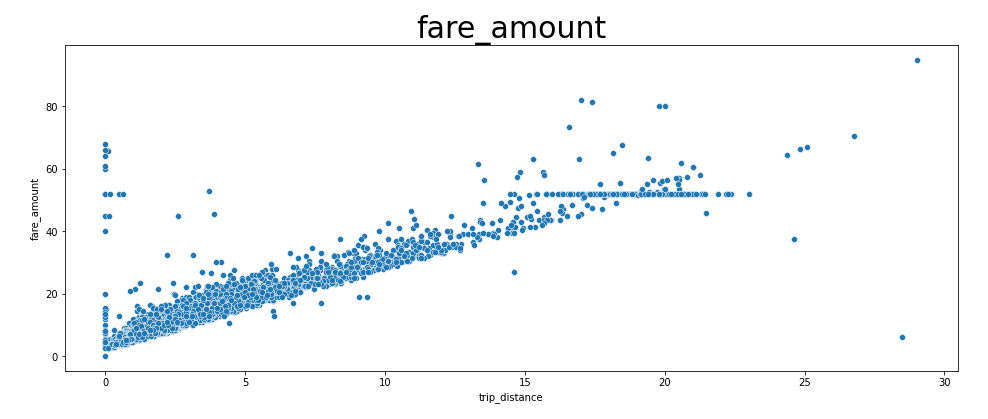
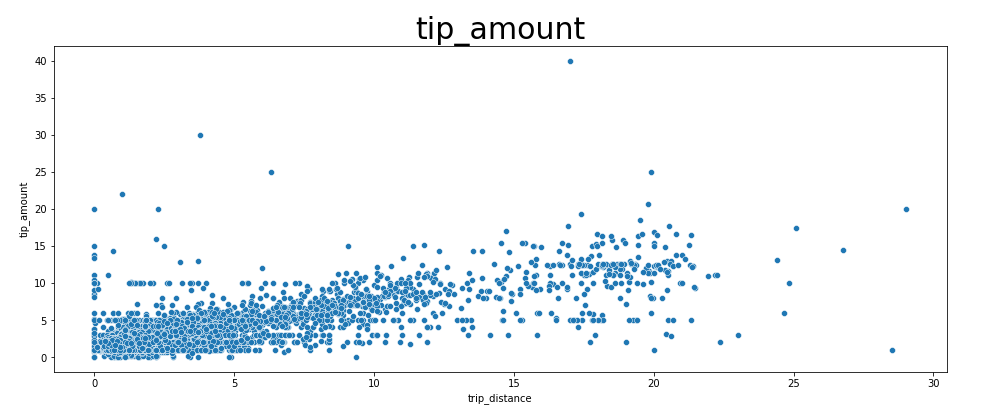
[거리와 요금 데이터의 산포도]
요금은 애초에 거리에 비례함으로 그래프는 당연한 결과다.
[거리와 팁 데이터의 산포도]
팁은 요금만큼이나 거리와 비례하진 않다.
거리가 10 mile 이하인 경우, 팁이 범위가 거의 비슷했다. 하지만 10 mile이 넘어갈수록 팁도 조금씩 증가함을 확인할 수 있다.
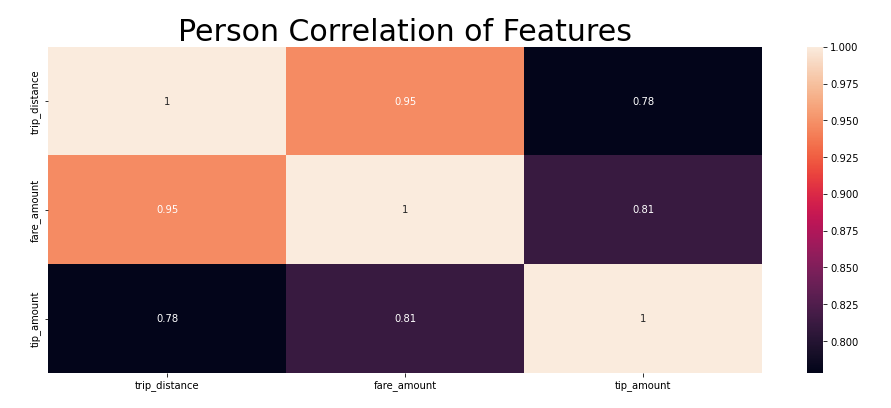
[거리, 요금, 팁의 상관관계 히트맵]
거리 & 팁의 상관관계 : 0.78
거리 & 요금의 상관관계 : 0.95
요금 & 팁의 상관관계 : 0.81
이들은 매우 중요한 결과다. 특히 요금이 커질 수록 팁도 커진다는 것은, 곧 거리가 멀어지면 팁도 커질 확률이 큼을 의미한다.
C. 장소별 Fare, Tip 관계 분석
장소에 따라서 요금과 팁이 달라질까? 확인한 결과, 장소에 따라 요금과 팁의 평균이 천차만별로 나뉨을 확인했다. 데이터에 포함된 장소가 워낙 많아서, Top 5으로 요금과 팁이 높은 장소를 추렸다.
# pzone
query = '''
SELECT
c.pzone,
MEAN(c.trip_distance) AS distance_mean,
MEAN(c.fare_amount) AS fare_mean,
MEAN(c.tip_amount) AS tip_mean
FROM
cleaned c
GROUP BY
c.pzone
ORDER BY
fare_mean desc
LIMIT 5
'''
pzone_df = spark.sql(query).toPandas()
# 그래프 그리기
fig, ax = plt.subplots(figsize=(16,6))
plt.title('Top 5 pzone in fare_mean', fontsize = 30)
sns.barplot(
x = 'pzone',
y = 'fare_mean',
data = pzone_df
)
--------
# pzone
query = '''
SELECT
c.pzone,
MEAN(c.trip_distance) AS distance_mean,
MEAN(c.fare_amount) AS fare_mean,
MEAN(c.tip_amount) AS tip_mean
FROM
cleaned c
GROUP BY
c.pzone
ORDER BY
tip_mean desc
LIMIT 5
'''
pzone_df = spark.sql(query).toPandas()
# 그래프 그리기
fig, ax = plt.subplots(figsize=(16,6))
plt.title('Top 5 pzone in tip_mean', fontsize = 30)
sns.barplot(
x = 'pzone',
y = 'tip_mean',
data = pzone_df
)
-------
# dzone
query = '''
SELECT
c.dzone,
MEAN(c.trip_distance) AS distance_mean,
MEAN(c.fare_amount) AS fare_mean,
MEAN(c.tip_amount) AS tip_mean
FROM
cleaned c
GROUP BY
c.dzone
ORDER BY
fare_mean desc
LIMIT 5
'''
dzone_df = spark.sql(query).toPandas()
# 그래프 그리기
fig, ax = plt.subplots(figsize=(16,6))
plt.title('Top 5 dzone in fare_mean', fontsize = 30)
sns.barplot(
x = 'dzone',
y = 'fare_mean',
data = dzone_df
)
--------
# dzone
query = '''
SELECT
c.dzone,
MEAN(c.trip_distance) AS distance_mean,
MEAN(c.fare_amount) AS fare_mean,
MEAN(c.tip_amount) AS tip_mean
FROM
cleaned c
GROUP BY
c.dzone
ORDER BY
tip_mean desc
LIMIT 5
'''
dzone_df = spark.sql(query).toPandas()
# 그래프 그리기
fig, ax = plt.subplots(figsize=(16,6))
plt.title('Top 5 dzone in tip_mean', fontsize = 30)
sns.barplot(
x = 'dzone',
y = 'tip_mean',
data = dzone_df
)
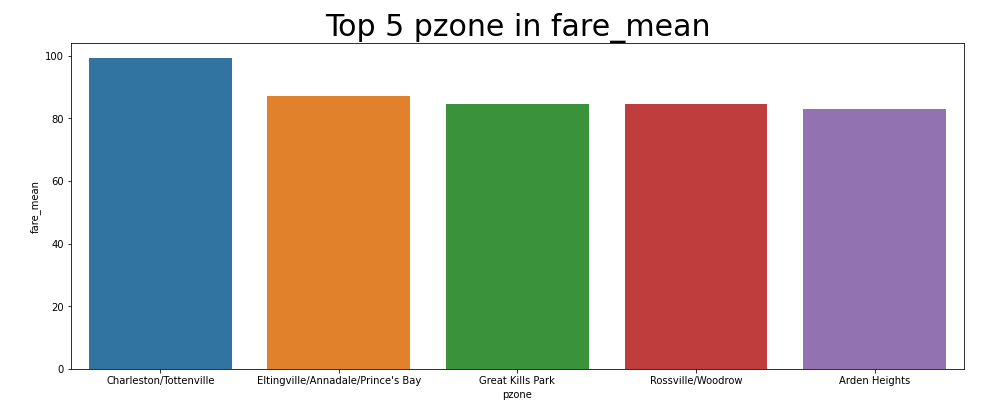
[Pickup zone : 요금 TOP 5]
승차 지역 중 요금 Top 5는 다음과 같다.
1위. Charleston/Tottenville
2위. Prince's Bay/Annadale
3위. Great Kills Park
4위. Rossville/Woodrow
5위. Arden Heights
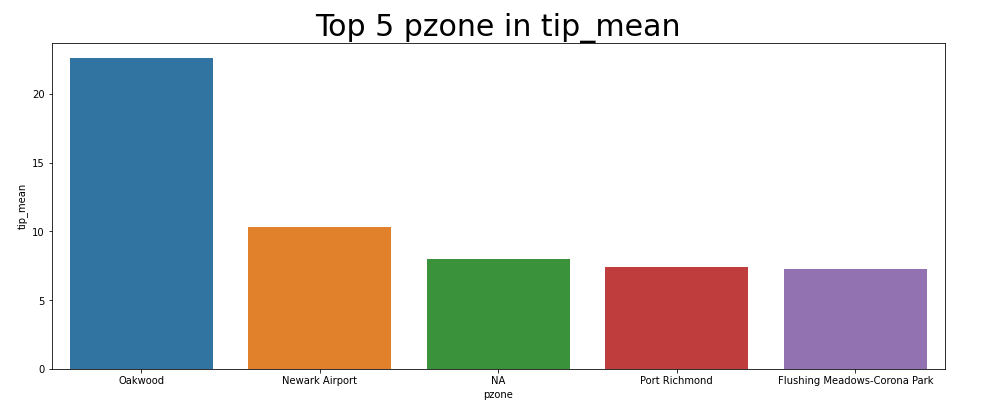
[Pickup zone : 팁 TOP 5]
승차 지역 중 팁이 가장 많은 Top 5이다. 요금이 많이 나오는 지역과 다소 다름을 확인할 수 있다.
1위. Oakwood
2위. Newark Airport
3위. NA
4위. Port Richmond
5위. Flushing Meadows-Corona Park
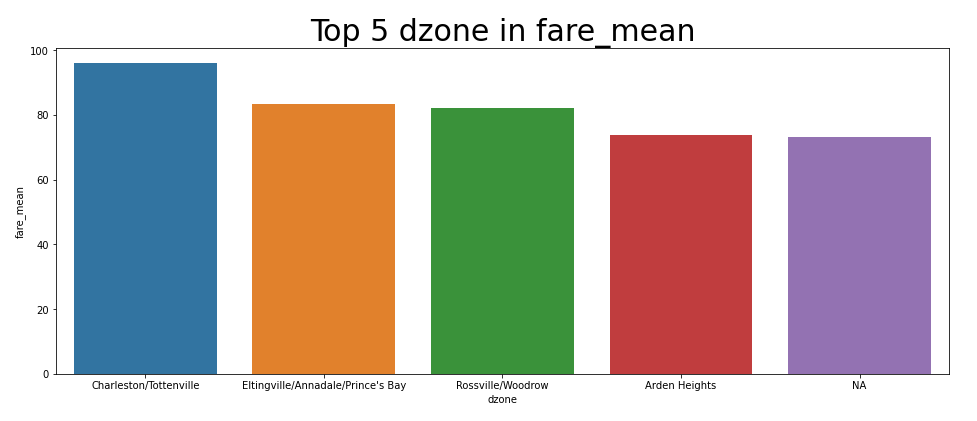
[Dropoff zone : 요금 TOP 5]
하차 지역 중 요금이 Top 5인 곳들이다. 승차 지역 Top 5와 꽤 비슷하다!
1위. Charleston/Tottenville
2위. Prince's Bay/Annadale
3위. Rossville/Woodrow
4위. Arden Heights
5위. NA
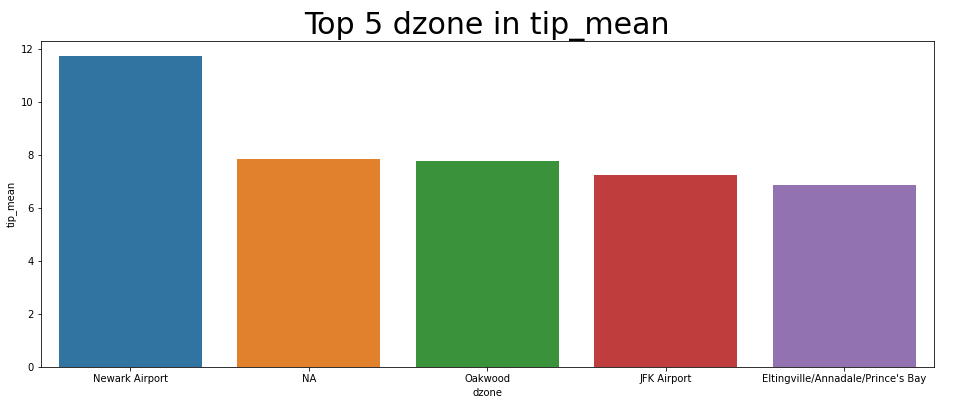
[Dropoff zone : 팁 TOP 5]
하차 지역 중 팁이 Top 5인 곳들이다. 승차 지역 팁 Top 5와 거의 비슷하며, JFK Airport만 다르다.
1위. Oakwood
2위. NA
3위. Oakwood
4위. JFK Airport
5위. Prince's Bay/Annadale
이 모두를 뉴욕 지도에 나타내면 다음과 같다.

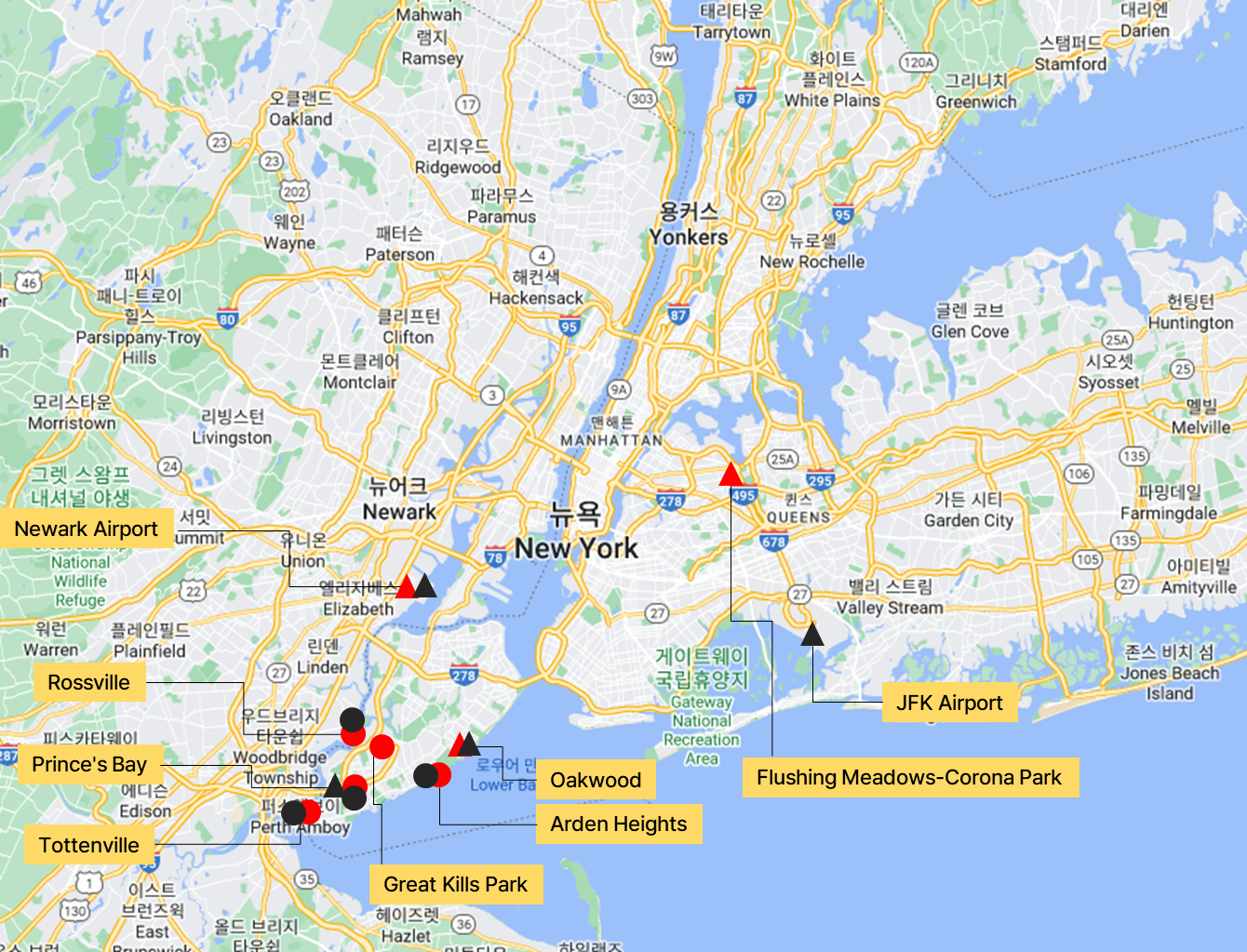
이전 포스팅에서 알아본 손님이 많은 지역은 뉴역 번화가였다.
하지만 요금, Tip이 많은 지역은 그보다 멀직히 떨어진 곳들이다. 이곳들은 보통 번화가와 떨어져 있기에, 승차하면 먼 곳으로 가기에 요금을 많이 내야 한다. 또 이곳들에 하차하려면 먼 곳에서 와야 하기에 또 요금을 많이 내야 한다. 요금도 많고 거리도 크니 팁도 자연스레 커지는 것이다. 아무래도 마냥 팁과 요금이 많다고 좋아해서는 안되는 것 같다. 요금, 팁을 좀 더 많이 얻으려다 사람이 없는 곳으로 가서, 다음 손님을 못 받을 수 있기 때문이다.
D. Fare, Tip 예측하기
Fare, Tip과 다른 변수들간의 상관관계는 어느 정도 파악했다. 이젠 머신러닝 모델을 통해 아예 예측하는 봇을 만들어보자. 알아서 상관관계를 파악해서 예측해 줄 테니 기사들에겐 이보다 수월한 의사결정 도우미가 없을 것이다.
데이터 전처리 과정과 모델 하이퍼 파라미터 튜닝 과정은 이전 포스팅에서 다뤘었다. 코드가 이해되지 않을 경우, 이전 포스팅에서 보고 오길 바란다.
Fare 예측 변수 : 승차 장소, 하차 장소, 요일, 승객 수, 거리, 승차 시간
Tip 예측 변수 : 승차 장소, 하차 장소, 요일, 승객 수, 거리, 승차 시간, 지불 방법
# fare 예측 모델 ------------------------------------------------------------
# 전처리 파이프라인
transform_stages = stages
pipeline = Pipeline(stages = transform_stages)
fitted_transformer = pipeline.fit(train_df)
vtrain_df = fitted_transformer.transform(train_df)
vtest_df = fitted_transformer.transform(test_df)
# 모델링 및 학습
model = lr.fit(vtrain_df)
# R2
model.summary.r2
결과 : 0.8121402678393606
# 모델 저장
model_dir = "C:/DE study/data-engineering/01-spark/data/model"
model.save(model_dir)
# tip 예측 모델 ------------------------------------------------------------
# 전처리 파이프라인
transform_stages = stages
pipeline = Pipeline(stages = transform_stages)
fitted_transformer = pipeline.fit(train_df)
vtrain_df = fitted_transformer.transform(train_df)
vtest_df = fitted_transformer.transform(test_df)
# 모델링 및 학습
model2 = lr.fit(vtrain_df)
# R2
model2.summary.r2
결과 : 0.46363365869062256
# 모델 저장
model_dir = "C:/DE study/data-engineering/01-spark/data/model"
model2.save(model_dir)
팁 예측 모델의 성능이 좀 낮다... 일단 주어진 칼럼에서 최선으로 보이므로, 넘아가자!
E. Fare, 팁 예측해서 콜 조언해주는 API
대망의 Fare, Tip 예측 API다. 전처리 파이프라인까지 굳이 올리진 않았다. 앞에서 설정한 변수에 맞춰 파이프라인을 구축했고, 이에 맞는 모델을 불러와서 Fare, Tip을 예측한다.
from pyspark.sql.types import StructType,StructField, StringType, IntegerType
def fare_tip_API(pickup_id, dropoff_id, day_of_week, passenger, distance, pickup_time, p_type):
columns = ['pickup_location_id', 'dropoff_location_id', 'day_of_week',
'passenger_count', 'trip_distance', 'pickup_time', 'p_type']
data = [(pickup_id, dropoff_id, day_of_week, passenger, distance, pickup_time, p_type)]
rdd = spark.sparkContext.parallelize(data)
df = rdd.toDF(columns)
df_t = fitted_transformer.transform(df)
df_t_2 = fitted_transformer_2.transform(df)
fare_prediction = lr_model.transform(df_t)
tip_prediction = lr_model2.transform(df_t_2)
fare_prediction = fare_prediction.select(fare_prediction.prediction)
fare = fare_prediction.rdd.flatMap(list).first()
tip_prediction = tip_prediction.select(tip_prediction.prediction)
tip = tip_prediction.rdd.flatMap(list).first()
return fare, tip
시나리오 상황
따뜻한 주말, 일요일 아침 6시에 당신은 택시를 운전하고 있다.
콜이 들어왔다.
승차 장소는 Queens Astoria(7) 이고, 하차 장소는 Brooklyn Bay Ridge(15)이다. 거리는 대략 17 mile. 승객은 두 명이다. 계산은 현금으로 하겠다고 한다. 지금 당장 요금과 팁을 예측하라!
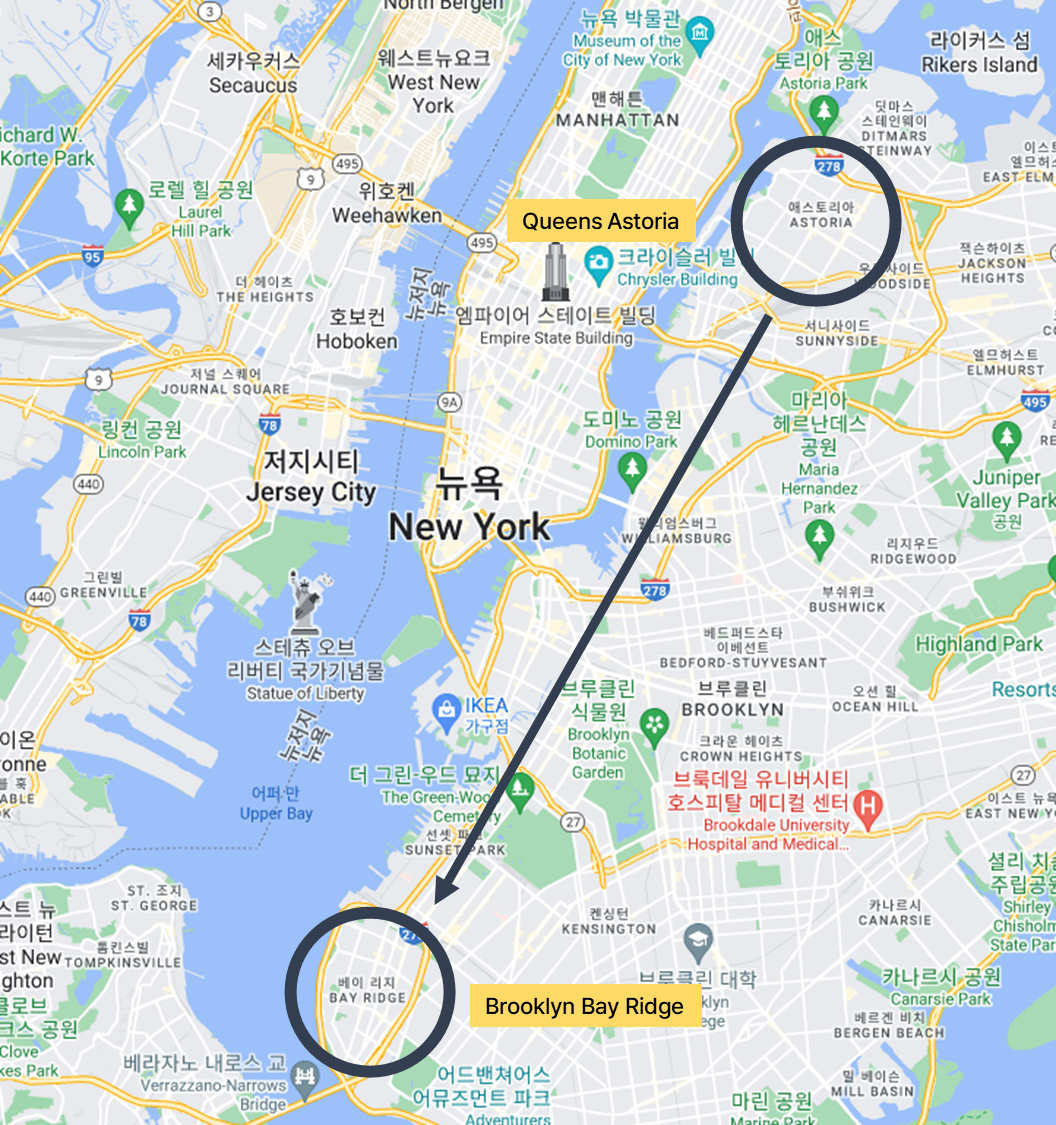
fare, tip = fare_tip_API(7, 15, 0, 2, 17, 6, "Cash")
print(f'예상 요금은 {fare} 입니다.')
print(f'예상 팁은 {tip} 입니다.')
예상 요금은 42.24078328599208 입니다.
예상 팁은 3.6536566893473803 입니다.
예상 요금 : 42.2 달러
예상 팁: 3.65 달러
콜을 받을 것인지 말 것인지는 당신의 몫이다!
전략 3. 현금 결제
대망의 마지막 꼼수다. 손님을 태워서 돈을 열심히 벌었다면, 세금을 최대한 안껴서 살아남아야 한다.
* 본 발언은 글쓴이의 삶의 태도와는 연관있지 않습니다.
손님이 현금 결제를 할 경우, 세금을 피해갈 수 있다. 그냥 소득 신고를 안 하면 그만이기 때문이다.
따라서 어떤 장소, 어떤 손님을 태울 때 현금을 받을 수 있는지 분석해보자.
[현금과 신용카드 결제의 빈도수]
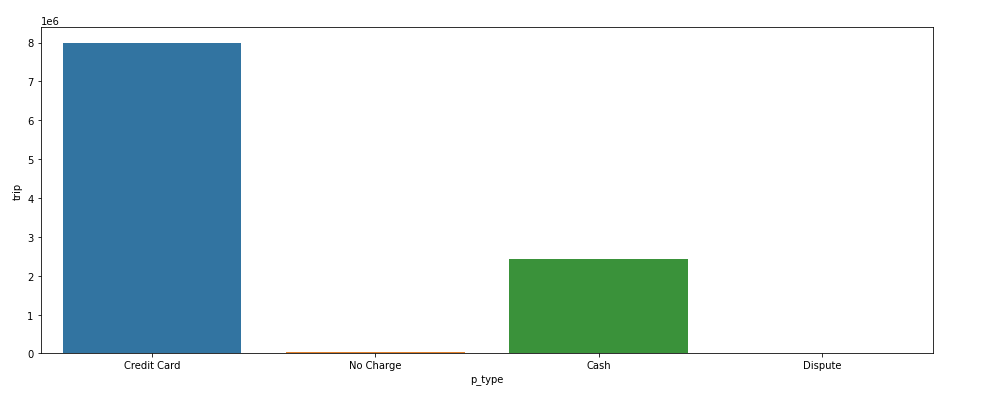
역시 요즘은 신용카드를 많이 쓴다.
[현금과 신용카드의 팁 평균]
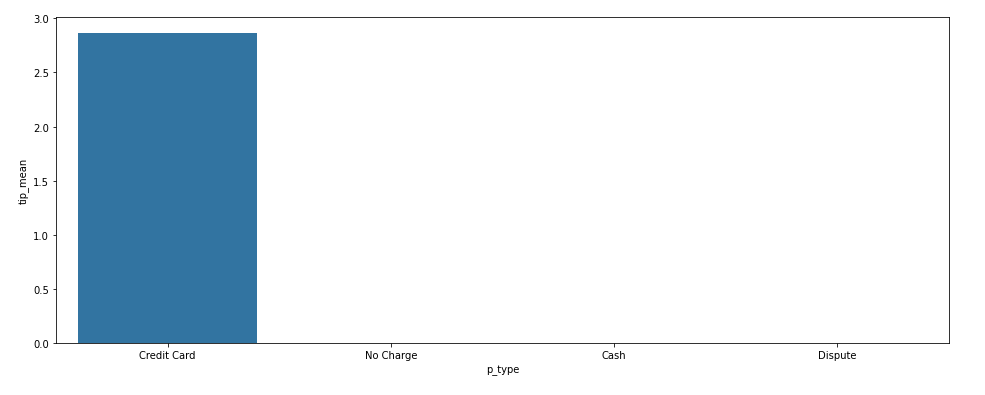
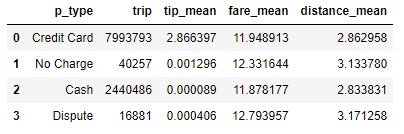
예상치 못한 일이 발생했다. 현금으로 팁을 준 경우가 거의 없다고 나왔다. 절대 있을 수가 없는 일이라 데이터를 다시 확인했는데 계속 똑같은 결과가 나왔다. 한 가지 유추한 것은,

팁도 소득에 포함되기 때문에, 현금 결제를 한 경우 그냥 팁을 꿀꺽한 것 같다. 어쩌면 당연한 결과라서 납득이 된다. 이에 따라 현금&카드에 따른 팁 크기의 변화는 알 수 없게 되었다. 팁 말고 요금, 거리 측면은 비슷한 결과가 나왔다.
지금까지 택시데이터를 이용하여, 어떻게 하면 택시로 돈을 더 벌 수 있을지 고찰해 보았다. 위의 분석들을 곱씹어보며 당신의 택시 전략을 새롭게 세워보길 바란다!
여기까지 오느라 고생하셨습니다.
'🧪 Data Science > Analytics' 카테고리의 다른 글
| [Analytics] 미국 택시로 생존하는 방법 (1) feat. TLC (0) | 2022.05.12 |
|---|---|
| [Analytics] 주간보호센터 고객, 위치 데이터 분석 [2] (3) | 2022.03.26 |
| [Analytics] 주간보호센터 고객, 위치 데이터 분석 [1] (0) | 2022.03.23 |