2024. 7. 3. 17:51ㆍ🧪 Data Science/Paper review
이번 포스팅에서 리뷰할 논문은
'Towards maximizing expected possession outcome in soccer(2023)' by Pegah Rahimian
https://journals.sagepub.com/doi/10.1177/17479541231154494?icid=int.sj-full-text.similar-articles.4
딥러닝 신경망을 이용하여 팀의 대략적인 strategy를 파악하고, 거기 위에 강화학습을 하여 Optimal policy를 찾아내는 논문이다. 키워드는 RL과 축구가 되겠다.
** 이 포스팅의 모든 figure과 표는 리뷰 논문에서 가져온 것임을 밝힌다.
1. Important Question
- How to split the whole game into different game phases and expound the short/long-term objectives accordingly to address the non-stationary nature of decision making in soccer?
- How to analyze the current strategy of a team, and obtain the optimal strategy?
- How to evaluate the obtained optimal strategy without the cumbersome and expensive process of applying it in a real match?
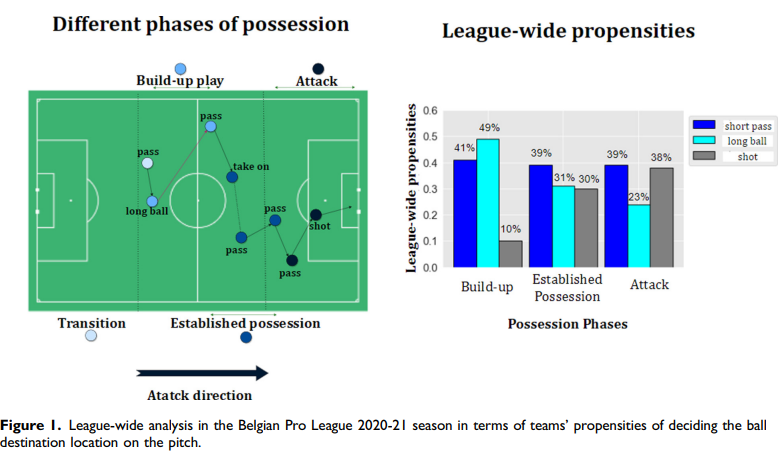
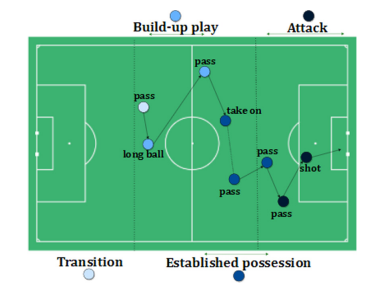
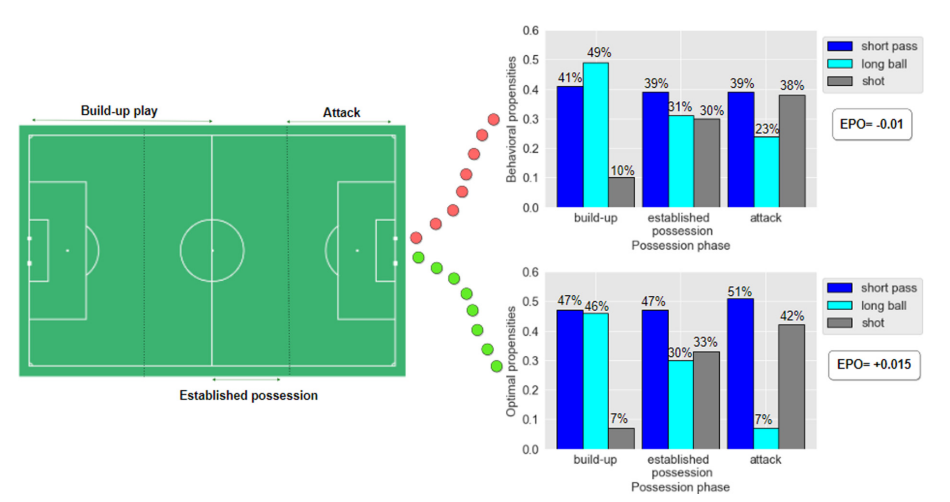
축구에서 phases가 크게 4개로 나뉜다고 보았음. Transition, Build-up play, Established possession, Attack. 축구 강화학습을 진행한 결과, 모든 페이즈에서 short passes가 제안되었고, short shots가 추구되었다.
논문의 work
- 딥러닝으로 ball의 목표 지점을 선택하는 팀의 경향 관점에서 팀 전략을 분석하고
- 똑같은 모델에 대해 주어진 보상을 기반으로 RL을 활용하여 볼과 선수들의 위치를 고려한 optimal tactics를 발견한다.
Dataset
- (x, y) of 22 players, the ball at 25 observations per second
- event data: on-ball action types(passes, dribbles..) with additional features
- every 0.04초에 모든 데이터 존재하도록 merge
Team’s behavior prediction method : In order to represent these propensities for any situation of the game and use them for further decision making, we need to estimate two probabilities
- The selection probability surface
- The success probability surface
2. State Representation
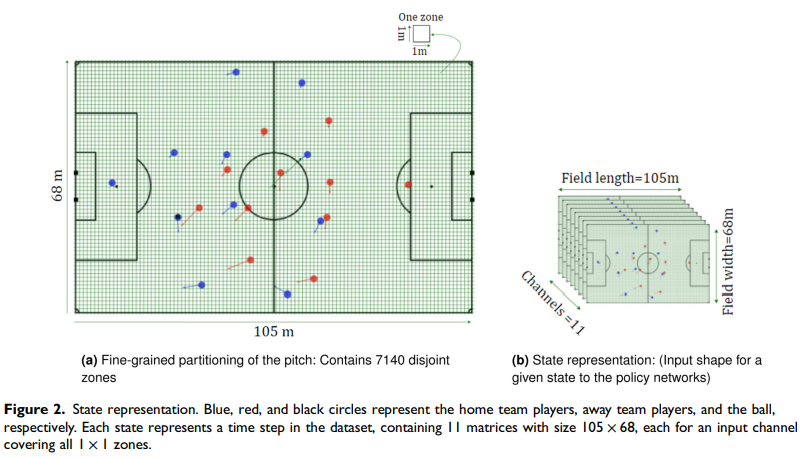
총 11개의 Input Channels로 이뤄져 있다. 선수들의 x, y 좌표, 골대와의 거리 및 각도 등 물리적 데이터들이 11개의 channels로 겹겹이 쌓여있다고 보면 된다.
3. Policy network architecture
: 확률 표면을 추론하고, 정책을 형식화 하기 위해 deep learning 기술 활용.
policy network = neural network that takes a huge number of game states as input and produces the probability surfaces as outputs.
2개의 probability surface을 아웃풋으로.
- Selection surface as policy
- Success surface
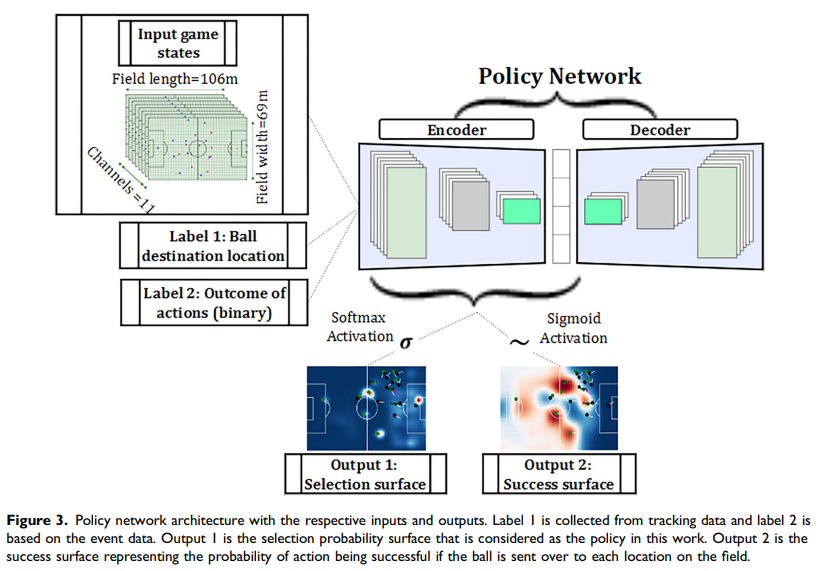
Surface는 deep learning으로 추론 ⇒ CNN-GRU가 가장 우수한 성능을 보임 ”we use the trained CNN-GRU model as our policy network in the rest of the paper”
Selection surface 자체가 policy 로 작동하기 때문에, CNN-GRU를 policy로 사용한다.
의문 1) policy는 대상의 행동 양식인데..?
대답 1) selection probability 자체가 선수 혹은 팀의 선택 방향성을 나타낸다!
4. Optimization method
: 이미 game state를 위해 selection/success probability surface를 마련함.
팀 분석을 통해 나온 selection surface는 optimal 하다고 할 수 없으며, success surface는 short-term 한 보상이 될 것임. 애초에 success 자체가 possession에 중점을 둔 것이기 때문임.
”we elaborate on our proposed optimization algorithm that can estimate the optimal full probability surfaces”
5. Markov decision process(MDP) : (S, A, R, π)
→ 볼 소유자가 볼 최종 위치 선택하는 확률을 모델링한다.
- Episode(τ): 처음 Event로부터 우리팀 볼이 (골, 빼앗김, 소유를 잃음) 등으로 통제권을 잃기 전까지 지속.
- State(s): player, ball의 위치, 속도, 거리, 골과의 각도 등 input channels. two absorbing staets(goal scoring and loss of possession)
- Action space(a): two types of action space. a continuous action space selected by ball carrier + specific action like short pass, long ball and shot.
- Policy(π): the probability with which the ball carrier selects any specific location on the field.
- Reward signal(R(s,a)): goal 상황으로만 reward 잡는 것은 too sparse. field를 4개의 phase로 나누어서 각각 다른 보상함수를 적용한다. 성공(kept possession), 실패(loss of possession)에 따라 reward를 다르게 준다. 실패의 경우, negative of the expected-goals value for the opponent’s shot(xG). 성공의 경우, 4개의 보상 함수를 phase에 따라 적용.
Reward-1) Transition: From start of the possession until the player completes the first pass or loses the ball.
objective: move the ball away from contact and change the horizontal channel
reward: 상대팀을 3개의 pressure clusters로 나누고, destination과 각 cluster의 centroid와의 거리를 반영함. P(s)는 success probability를 의미.

Reward-2) Build-up: Start from playing in their own half until the ball reaches the opposition half.
objective: Looking for opportunities to break through the midfield line of the opponent team
reward: attack 팀의 점수가 defense 팀의 점수보다 높냐, 낮냐에 따라 reward가 다르게 적용된다.
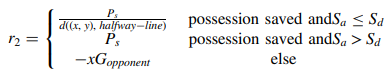
Reward-3) Established possession: From the first pass in the opposition’s half until the final third of the pitch with over two consecutive actions.
objective: Retain possession
reward: larger reward to the actions moving the ball to the location on the pitch with the most success probability

Reward-4) Attack: Having controlled possession in the attacking third.
objective: Creat chance and goal scoring
reward: larger reward to the actions moving the ball to the location on the pitch with a higher success probability and a higher expected goals value
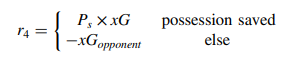
6. Objective function: expected possession outcome
: EPO is a real-valued number in the range (-1, 1). The value can be interpreted as the likelihood of the respective possession ending in a goal for the attacking team (1) or a goal for the opposing team (-1). 결국 마지막은 골로 끝날 확률을 가리킨다. 따라서 can be regarded as the objective function of our optimization framework to be maximized.
최적의 solutions를 찾기 위해 RL을 적용, Policy Gradient(PG) algorithm을 활용했다. PG algorithm
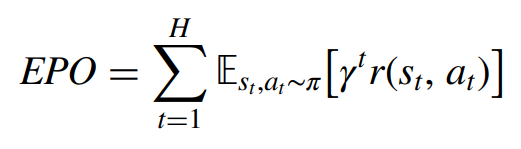
- offline RL workflow without online interaction with the environment.
- The policy network presented in the previous는 기존 선수들의 behavioral policy를 이끌어내기 위한 용도 ↔ 지금은 거기서 최적화를 시킨다.
actual possession policy ⇒ optimal possession policy

7. Result
: the behavioral policy vs optimal policy ⇒ 비교는 OPE(Off-policy Policy Evaluation method)를 통해.
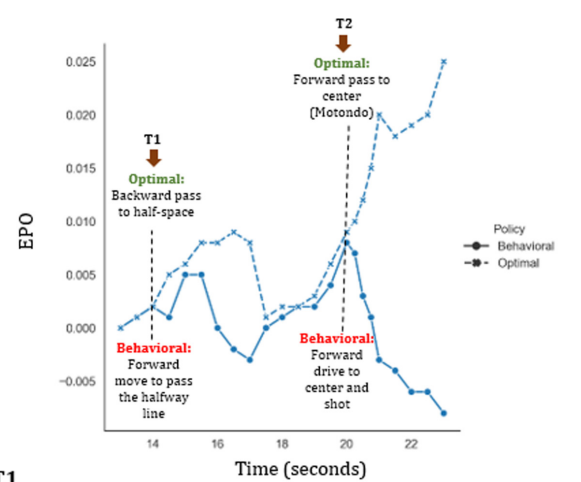
optimal policy 적용했을 때, EPO 점수가 크게 나온다.
optimal 했을 때, short pass 증가하고 long ball 줄어든다. 특히 Attack 지점에서 short pass로 공을 운영하다가 shot 하는 비율 증가.
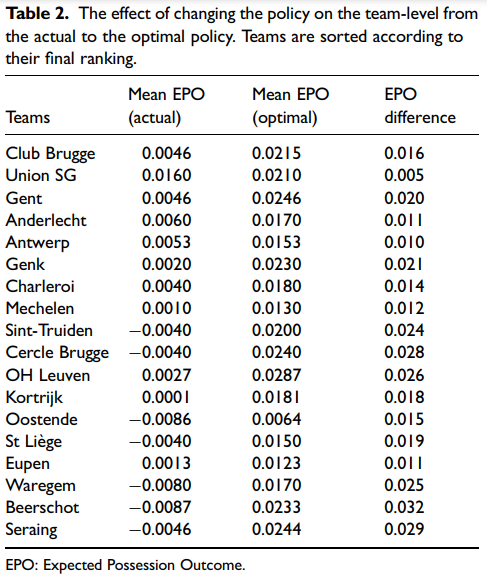
여러 구단들에 대하여 기존 전략 분석 및 optimal policy 적용 결과, 모든 팀의 EPO를 증가시킬 수 있음을 보임.
향후 연구 과제
- multi-agent를 통해 opponent team도 최적의 전략 학습 시킨다. (competition 방법)
- 개별 선수들의 기여도를 포착하기 위한 framework로 확장시킬 수 있다.
'🧪 Data Science > Paper review' 카테고리의 다른 글
| [논문리뷰] Sample-Efficient Multi-agent RL with Reset Replay (5) | 2024.11.11 |
|---|---|
| [Paper review] TabNet: Attentive Interpretable Tabular Learning 및 TabNet 실습 (0) | 2024.09.13 |
| [논문 리뷰] 딥러닝으로 혐오 표현 감지하기 in Tweets (0) | 2022.04.06 |
| [논문 리뷰] Attention Mechanism 기법, NLP (0) | 2022.04.03 |
| [논문 리뷰] CNN for Sentence Classification, 문장 분류를 CNN으로 시도하다. (0) | 2022.03.16 |