2025. 4. 18. 14:30ㆍ🧪 Data Science/Paper review
요즘 UNIST 인공지능 연구실에서 인턴을 하고 있다.
목요일마다 세미나 발표를 하는데, SAC 논문을 읽고 리뷰를 했다.
리뷰 내용을 블로그에 간략하게 정리한다.
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
https://arxiv.org/abs/1801.01290
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Model-free deep reinforcement learning (RL) algorithms have been demonstrated on a range of challenging decision making and control tasks. However, these methods typically suffer from two major challenges: very high sample complexity and brittle convergenc
arxiv.org
[1] SAC 논문의 핵심
1-1. Off Policy에 Entropy Maximization framework를 적용해서, 샘플 효율성과 Robustness를 동시에 가져오고자 함.
1-2. Soft Policy Iteration 방식을 개선한 모델로, tabular 방식의 Q를 Function Approximation으로 대체하여 continuos 환경에서도 SAC가 활용될 수 있도록 함.
1-3. Policy를 Q로부터 Boltzmann 및 KL-Divergence를 통해 유도하는 것이 아니라, 파라미터화하여 직접 explicit 하게 업데이트함.
1-4. 결국 Critic(Q-network), Actor(Policy-network) 형태를 띠게 됨.
[2] SAC 논문의 아쉬운 점
2-1. Deadly Triad(off policy, function approximation, bootstrapping 동시 적용 시 수렴 증명 X)를 직접적으로 해결하지 못하고, Soft Policy Iteration(off, tabular, bootstrapping)에서만 수렴을 증명함. 따라서 논문이 내세웠던 contribution인 Convergence Proof가 진정한 의미에서 제시되었다고 볼 순 없음(박사님들에 의하면, 후속 논문에서 제시되어 있다고 하심)
2-2. Hyperparameter에 대해 민감하지 않다는 것을 SAC의 contribution으로 삼았음. 이것을 증명하기 위해선 민감도 실험이 이뤄져야 하는데, 이에 대한 직접적인 실험은 없는 것으로 확인됨. 다른 모델과 비교했을 때, average score가 상대적으로 안정적 상승한다는 점을 들어 간접 증명한 것으로 보임.
[3] SAC 논문을 이해하기 위해 알아두면 좋은 사전 지식
3-1. Entropy definition and Entropy Maximization framework in RL
3-2. Likelihood ratio and Reparameterization trick
3-3. Importance Sampling
3-4. Poliy iteration and A2C
3-5. KL-Divergence, its equation about Objective function
[4] SAC 알고리즘 및 Q/Value/Policy network의 목적함수

논문의 알고리즘은 다음과 같다.
4-1. 학습 시작 전에 모든 파라미터 초기화
4-2. Step을 밟으면서 현재 policy로 Replay Buffer에 경험 축적
4-3. Network 별로 각 Gradient Step에 따라 업데이트 진행
Q/Value/Policy의 목적함수는 다음과 같다.
확률에 log를 씌어서 entropy 지수로 변환함. 이를 보상과 같이 최대화하도록 objective function을 설계하여 업데이트.


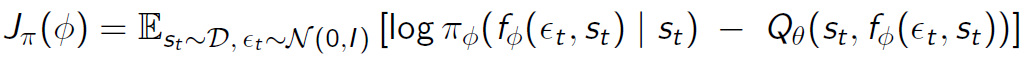
[5] SAC 실험 결과 및 Ablation Study
5-1. 환경: MuJoCo, rllab의 Continuos
5-2. Comparative Experiment Result: Walker 환경을 제외하곤 모든 환경에서 좋은 성능을 보임

5-3. Ablation Study: stochastic vs deterministic
SAC는 policy network를 mean/std를 추정하게 하여 확률 분포에서 action을 뽑는 식.
하지만 이때 stochastic policy가 아니라 deterministic(확률적 X) policy를 이용할 경우, 성능이 stochastic보다 높아지는 순간도 있지만, 전체 학습 평균(seed 평균)을 냈을 땐 오히려 성능이 떨어지는 모습을 보임. 학습 추이도 stochastic이 안정적임을 볼 수 있음.

5-4. Ablation Study: Evaluation, Reward scale, Target Smoothing
학습 중 성능 test할 때, policy로부터 나온 action을 stochastic하게 샘플링한 경우가 policy network로부터 나온 평균값을 이용(deterministic)하는 것보다 성능이 낮게 나옴. 보상 정규화와 타겟 네트워크의 지수평균 파라미터는 적당하게 설정될 때 좋은 성능을 보임.
이때, 보상 정규화는 entropy의 반영 비율과도 연결이 되는데, 큰 값으로 정규화를 했다면 entropy 영향력이 커진다는 것을 확인해두어야 함.

'🧪 Data Science > Paper review' 카테고리의 다른 글
| [논문리뷰] Sample-Efficient Multi-agent RL with Reset Replay (5) | 2024.11.11 |
|---|---|
| [Paper review] TabNet: Attentive Interpretable Tabular Learning 및 TabNet 실습 (0) | 2024.09.13 |
| [Paper review] Towards maximizing expected possession outcome in soccer (0) | 2024.07.03 |
| [논문 리뷰] 딥러닝으로 혐오 표현 감지하기 in Tweets (0) | 2022.04.06 |
| [논문 리뷰] Attention Mechanism 기법, NLP (0) | 2022.04.03 |